����ժҪ��ժҪBeautifulSoup����python�Z���P(gu��n)�ھW(w��ng)�j(lu��)���x��ȡ�������ĵ������졣���ܸ���(j��)html��xml�Լ�html5lib�Z�����������䣬�M(j��n)����Ч�����W(w��ng)퓃�(n��i)�ݡ����ďĻ���Ԫ�ء��W(w��ng)퓃�(n��i)�ݱ�v��ȡ�������ֽ�BBeautifulSoup��Ĺ���ԭ�������Y(ji��)�����ƽ�_���µĈD���N�۔�(sh��)��(j��)��
����ժҪBeautifulSoup����python�Z���P(gu��n)�ھW(w��ng)�j(lu��)���x��ȡ�������ĵ������졣���ܸ���(j��)html��xml�Լ�html5lib�Z�����������䣬�M(j��n)����Ч�����W(w��ng)퓃�(n��i)�ݡ����ďĻ���Ԫ�ء��W(w��ng)퓃�(n��i)�ݱ�v��ȡ�������ֽ�BBeautifulSoup��Ĺ���ԭ�������Y(ji��)�����ƽ�_���µĈD���N�۔�(sh��)��(j��)�錍(sh��)�����M(j��n)����ȡ��Ϣ�Ľ���չʾ��
�����P(gu��n)�I�~�W(w��ng)�j(lu��)���x;�W(w��ng)퓽���;BeautifulSoup��
����1����
����BeautifulSoup����python�Z�Եĵ��������x�����졣���ṩ�˺��α�ݵ�pythonʽ����(sh��)��̎���(f��)�s��Web���ķ��������ǽ�������v���S�o(h��)��(bi��o)����Ĺ��졣BeautifulSoup�첻�H֧��html��߀֧��lxml�Լ�htnl5lib��������ͨ�^�����ęn���Ñ���ȡ�Ѓrֵ�Ĕ�(sh��)��(j��)�����(ji��)ʡ�_�l(f��)�r�g���ɞ�V�ܚgӭ�ľW(w��ng)퓽�������֮һ[1]��
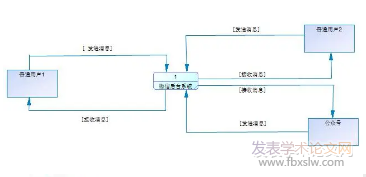
����2BeautifulSoup���ʹ��
�����������x�@ȡ�W(w��ng)���Ϣ�����Ǐ�html���a�г�ȡ�҂���Ҫ����Ϣ��html���a�ɱ�����(bi��o)���M�ɡ�BeautifulSoup�����Ҫ���ܾ��Ǿ��_��λ��(bi��o)���Լ��Ę�(bi��o)������ȡ��(n��i)��[2]��
����2.1BeautifulSoup��Ļ���Ԫ��
����BeautifulSoup����Ԍ�html�ęn�D(zhu��n)�Q��һ����(f��)�s�Ę��νY(ji��)��(g��u)��ÿ����(ji��)�c(di��n)����һ���������Ќ�����Ԛw�{��4�(1)Tag����ÿһ��html�ęn�е�Tag��(bi��o)������BeautifulSoup��һ������(2)NavigableString����Tag����ă�(n��i)���ı���(ji��)�c(di��n)������ͨ�^Tag.string����ԓ����(3)BeautifulSoup����ͨ�^Č�(sh��)����BeautifulSoup������Ԍ�html�ęn�D(zhu��n)�Q��һ�����νY(ji��)��(g��u)���Ա�ʾhtml���ęn�Y(ji��)��(g��u)��(4)Comment������עጘ�(bi��o)�����ı���(ji��)�c(di��n)����NavigableString��������
����2.2BeautifulSoup�����Ϣ��ȡ����
����BeautifulSoup��������һ��html��(bi��o)���䣬���ڱ����ɘ�(bi��o)�����nj����ַ����M�ɵĹ�(ji��)�c(di��n)[3]�����ڹ�(ji��)�c(di��n)�ķǾ��ԽY(ji��)��(g��u)�������������ڵ�λ�ã�ʹ�����c������(ji��)�c(di��n)��(g��u)�������¡�ƽ���P(gu��n)ϵ���Ķ�������ԓ��(ji��)�c(di��n)�ĸ���(ji��)�c(di��n)���ӹ�(ji��)�c(di��n)���ֵܹ�(ji��)�c(di��n)�����б�v�����б�v��ƽ�б�v����(ji��)�c(di��n)�����б�v����ͨ�^�ӌO��(ji��)�c(di��n)��(sh��)�F(xi��n)��.contents���ԿɌ������ӹ�(ji��)�c(di��n)���б��ķ�ʽݔ����ͨ�^.children���������Ɍ������ӌO��(ji��)�c(di��n)�M(j��n)�б�v����(ji��)�c(di��n)�����б�v����ͨ�^��݅��(ji��)�c(di��n)��(sh��)�F(xi��n)��.parent���ԿɌ����и���(ji��)�c(di��n)���б��ķ�ʽݔ����ͨ�^.parents���������Ɍ����и�݅��(ji��)�c(di��n)�M(j��n)�б�v����(ji��)�c(di��n)��ƽ�б�v��ͨ�^�ֵܹ�(ji��)�c(di��n)��(sh��)�F(xi��n)��.next_sibling���ԫ@ȡ��ԓ��(ji��)�c(di��n)����һ���ֵܹ�(ji��)�c(di��n)��.
����previous_sibling�t�c֮�෴�������(ji��)�c(di��n)�����ڣ��t����None���ֵܹ�(ji��)�c(di��n)��ƽ�б�vҪ��ɹ�(ji��)�c(di��n)���ͬ����(ji��)�c(di��n)��������ͬһ������(ji��)�c(di��n)������(bi��o)�������ָ����(n��i)�ݵĹ�(ji��)�c(di��n)��v�t��Ҫ�������������ͬ���ã�BeautifulSoup���ṩ��8�N��Ϣ���Һͫ@ȡ����������ʹ����V����������find_all()����������(bi��o)����[4]��find_all(name,attrs,recursive,text,**kwargs)����������(d��ng)ǰtag�������ӹ�(ji��)�c(di��n)�����Д��Ƿ�����^�V���ėl����
������(j��ng)��(j��)Փ��Ͷ�忯�����(j��ng)��(j��)��(sh��)�W(xu��)��(����)��(chu��ng)����1984�꣬��Ҫ���ǔ�(sh��)����(j��ng)��(j��)�W(xu��)����(sh��)����(j��ng)��(j��)�W(xu��)��Ӌ����(j��ng)��(j��)�W(xu��)����(j��ng)��(j��)����Փ����(j��ng)��(j��)����Փ����(j��ng)��(j��)�A(y��)�y�c�Q�ߺͽ�(j��ng)��(j��)��(y��ng)�Ô�(sh��)�W(xu��)�I(l��ng)���Є�(chu��ng)���Ե��о��ɹ��������F(xi��n)�鼾���������(n��i)��_�l(f��)�С�
����3���ƽ�_�D�����N��(sh��)��(j��)����ȡ����
�����������ƽ�_����Ʒ�ɽ���(sh��)��(j��)�N(y��n)��������������Ϣ�������Ծ��|ƽ�_2020��10�·ݵĈD���N����Ϣ������(j��)������python��requests���BeautifulSoup����ȡ��������ԓ�r�ξ��|�D���N�۰��top100�l��Ϣ���Ԏ����Ñ��@ȡ�����T�D���YԴ��
����(1)��(sh��)��(j��)��ȡ���ڔ�(sh��)��(j��)��ȡ֮ǰ����x���|�W(w��ng)վ�ľW(w��ng)�j(lu��)robots�f(xi��)�h�����ڔ�(sh��)��(j��)���o(h��)�������W(w��ng)վ�����x�L���M(j��n)���˷����O(sh��)�ã���Ҫ�ľW(w��ng)�j(lu��)Ո���^�е�user-agent��Ϸ��g�[����Ȼ������requests��GET������Ŀ��(bi��o)�W(w��ng)��M(j��n)����ȡ���Ķ��@�î�(d��ng)ǰ����html�ļ���defaskURL(url):head={"user-agent":"Chrome"}r=requests.get(url,headers=head)r.raise_for_status()r.encoding=r.apparent_encodinghtml=r.textreturnhtml
����(2)��(sh��)��(j��)����������requests����ȡ���������W(w��ng)퓵�html�ęn�����д�?j��n)?sh��)��(j��)�������҂���Ҫ�ĈD�����N��Ϣ������BeautifulSoup���M(j��n)���Ѓrֵ��(sh��)��(j��)�Ľ�����ȡ��ͨ�^����soup��������find_all("div",class_="p-detail")�ҵ���l�ğ��N�D����Ϣ�����M(j��n)�Д�(sh��)��(j��)��ϴ��ֻ����D�����Q�������Լ���������Ϣ���惦���б픵(sh��)��(j��)��defgetData(html):html=askURL(url)soup=BeautifulSoup(html,"html.parser")data=[]foriteminsoup.find_all("div",class_="p-detail"):aset=item.find_all("a")data.append([aset[0].attrs['title'],"\t����"+aset[1].attrs['title'],"\t"+aset[2].attrs['title']])returndata
����(3)��(sh��)��(j��)���档��������ɵĔ�(sh��)��(j��)�����Ծ�̖����ŵ����أ����a��ʽ�O(sh��)�Þ�utf-8��������F(xi��n)�y�a[5]��defsaveData(datalist,savepath):withopen(savepath,"w",encoding="utf-8")asf:fordataindatalist:forlineindata:f.writelines(line)f.write("\n\n")return
���������īI(xi��n)
����[1]�K��.�ֲ�ʽ�W(w��ng)�j(lu��)���x���g(sh��)���о��c��(sh��)�F(xi��n)[�Tʿ�W(xu��)λՓ��].�����I���I(y��)��W(xu��),�����I,2012
����[2]������,���P(gu��n),��.Python�����O(sh��)Ӌ-�Ļ��A(ch��)���_�l(f��).����:���A��W(xu��)������,2017
����[3]����,�Y��,�S����.Python�Z�Գ����O(sh��)Ӌ���A(ch��).��2��.����:�ߵȽ���������,2017
����[4]������.����Python�ľW(w��ng)�j(lu��)���x�����O(sh��)Ӌ.��Ӽ��g(sh��)�cܛ������,2017(23):248-249
����[5]κٻ��,�R����,�һ�Q.���ھW(w��ng)�j(lu��)���x�ľ��|���ƽ�_��(sh��)��(j��)����.��(j��ng)��(j��)��(sh��)�W(xu��),2018,35(1):77-85
�������ߣ��ϻ�

�D(zhu��n)�dՈע�����l(f��)��W(xu��)�g(sh��)Փ�ľW(w��ng)��http://www.zpfmc.com/wslw/26786.html
