����ժҪ������Ϣ��(sh��)��(j��)�����������Į��£���(sh��)��(j��)�ھ��c�C���W�����g�w�ٰl(f��)չ�����У����]���g�ڸ�У�W���ČW�����������ѳɞ�һ�N�������dȤ�ۺ÷�����ʽ������ڿ��ٽ����W���ľC�ϳɿ��c�W���О�֮�g���P(li��n)�ȡ��ھ�?q��)W���W�����dȤ������ͬ�r�����F(xi��n)�����T�D���Ă��Ի���
��������Ϣ��(sh��)��(j��)�����������Į��£���(sh��)��(j��)�ھ��c�C���W�����g�w�ٰl(f��)չ�����У����]���g�ڸ�У�W���ČW�����������ѳɞ�һ�N�������dȤ�ۺ÷�����ʽ������ڿ��ٽ����W���ľC�ϳɿ��c�W���О�֮�g���P(li��n)�ȡ��ھ�?q��)W���W�����dȤ������ͬ�r�����F(xi��n)�����T�D���Ă��Ի����]���ѽ�(j��ng)�ɞ��У�о����l(f��)�W�������W���ķ���֮һ������������څf(xi��)ͬ�^�V�ĈD�����]�㷨��ͨ�^����У�W���ČW���О��M�Д�(sh��)��(j��)�����������f(xi��)ͬ�^�V�ĸ��ʾ��ģ�ͣ��Ķ��l(f��)�F(xi��n)�W���W�����dȤ�A��ֵ����K���F(xi��n)��?q��)W�����]���Ի��D����Ϣ��ƽ�_�Ĵ���Mһ������W���x���˸��dȤ�ĈD�����M����x���W���c֪�R��չ������У�@��(y��u)���W�L���O��
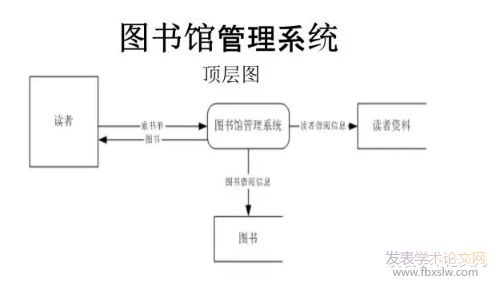
�������P�о�Ŀǰ����(n��i)�������]�㷨�ڌW���n�̌����c��Ȥƫ���е����P���}�M�����^��������о�����������ö�S�����g�P(li��n)Ҏ(gu��)�t��(sh��)��(j��)�ھ��g�����Åf(xi��)ͬ�^�V�㷨���P(li��n)�㷨����ͬ�Ñ�Ⱥ�w�D����醔�(sh��)��(j��)�M�з�����̽������ᘌ��ԵĈD�����]���ղ��ԣ������D���^����������
�����D���^Փ�ķ������r���D�������OӋ�ărֵȡ��̽��
��������Ӌ���Ñ�֮�g�������Բ��c���y(t��ng)�ąf(xi��)ͬ�^�V���]������Y(ji��)�ϣ�����˻����Ñ��dȤ���еĸ��M�f(xi��)ͬ�^�V�D�����]��������Ƽͨ�^���yԇ�����Ô�(sh��)��(j��)�ھ��g�ĈD�����]ϵ�y(t��ng)���]�ĕ�Ŀ�c���H��醵ĕ�Ŀ�����Ǻϣ��Д��ʴ_�Ԍ��Ȃ��y(t��ng)��ʽ�����ߡ�������Ҳ���һ�N�Y(ji��)��eƫ�õąf(xi��)ͬ�^�V���]�㷨����ԭ�㷨Ӌ���Ñ����ƶȵĻ��A�ϣ��Y(ji��)���Ñ�eƫ�õ����ƶȁ�Ӌ��������Ķ��õ����]�Y(ji��)����
�����F(xi��n)�еć���(n��i)�о������c���]�ڌ��f(xi��)ͬ�^�V��(sh��)��(j��)���P(li��n)Ҏ(gu��)�t�о��ϣ������ھ�?q��)W�����dȤ�A��ֵ��ꇽ����о��^�١��ڇ����о��У�TewariҲ�U���˸���(j��)�I�ҵ��dȤ���]�D�����^�c���������һ�N���ڃ�(n��i)���^�V���f(xi��)ͬ�^�V���P(li��n)Ҏ(gu��)�t�ھ���Y(ji��)�ϵĈD�����]ϵ�y(t��ng)��Parvatikarͨ�^�����څf(xi��)�����^�V���P(li��n)Ҏ(gu��)�t�ھ���Y(ji��)�ρ���Q�ھ��D�����]��(sh��)��(j��)ϡ���Ԇ��}���ԫ@�ø��õ����ܡ�
����Mathew���������һ�N���ڃ�(n��i)���^�V(CBF)���f(xi��)���^�V(CF)���P(li��n)Ҏ(gu��)�t�ھ�ĽM�������ĕ����]ϵ�y(t��ng)(BRS)���Ԯa(ch��n)����Ч����Ч�����]��������������څf(xi��)ͬ�^�V�����]�㷨���������څf(xi��)ͬ�^�V�ĸ��ʾ��ģ�͵ČW���dȤ�A���ھ��g���OӋ��һ�Nᘌ��dȤ�A�����]�Ă��Ի��D�����]ϵ�y(t��ng)�����_����?q��)W�����]���Ի��D����Ϣ����W��������Ϣ���ṩ������Ŀ�ġ����څf(xi��)ͬ�^�V�����]�㷨���õąf(xi��)ͬ�^�V�㷨�֞�ɷN�������Ñ��ąf(xi��)ͬ�^�V�㷨(user-basedcollaborativefiltering)���Լ�������Ʒ�ąf(xi��)ͬ�^�V�㷨(item-basedcollaborativefiltering)��
������ϵ�y(t��ng)��Ŀ������?q��)W���M�Ђ��Ի��D�����]�����û����Ñ��ąf(xi��)ͬ�^�V�㷨����(j��ng)�^�Ñ�ƫ�ö�S���u�֡������dȤ�A��Ӌ���c�P(li��n)���]�б�Ӌ��ó��ʴ_�ʺ��ٻ�����ߵĎ�����(y��u)���dȤ�A��Ӌ��Y(ji��)������S���u�ֶ�S���u����ָ�M�Ѕf(xi��)ͬ�^�V���]�Ļ��A�����о���ȡ���ڌW����Ŀ�ɿ����ղؕ�����������x�ٶȡ������u���c�u�r���О�Ĕ�(sh��)��(j��)����(j��)�W���О鷴�����Ñ��dȤ�A��?q��)����M�мә࣬��(j��ng)�^�p��͚wһ�����A̎�����Ñ�ƫ�ö��S���ģ�ͣ����Ñ��б��c��Ʒ�б����龕�ȳߘˣ��ó��Ñ���Ʒ��ƫ��ֵ��
�����dȤ�A��Ӌ���dȤ�A��Ӌ����ָ��(j��ng)�^��ꇷ����õ��Ñ�ϲ�úõ��Ñ��dȤƫ��������Ӌ���Ñ�֮�g�����ƶȡ��ڳ��õĚW����¾��x��Ƥ���d���Pϵ��(sh��)��Cosine���ƶȡ�Tanimotoϵ��(sh��)���dȤ�A���㷨�У����о�����Cosine���ƶȷ����������V��������Ӌ���ęn��(sh��)��(j��)�����ƶȣ�����xi�cyi�քe����x�Ñ��cy�Ñ���i���u�֣��ɂ������e�Ĕ�(sh��)ֵԽС�t���ƶ�Խ�ߡ�
�����P(li��n)���]�б��P(li��n)���]�б�����Ҫ���Խ�(j��ng)��Apriori�㷨�ھ��P(li��n)Ҏ(gu��)�t���@ȡ�������Ñ��c������Ʒ������(j��)�����Ñ���CF˼�룬�����Ñ��]��ƫ��ֵ�ĺ��x헼����ٸ���(j��)�P�I�~�l�ʺY�x�^�V��������С֧�ֶȵ��l��헼��������ȡ�����P(li��n)���P(li��n)���]�б���ץȡ����������(sh��)��(j��)���M�����]��
�����������څf(xi��)ͬ�^�V�ĈD�����]ϵ�y(t��ng)Ŀǰ����У�D���^�c��(sh��)���YԴ����H����D���YԴ����ṩ��Ϣ�z���c�ļ���ԃ���ܣ�ȱ����ᘌ��Ե���Ϣ���]���ܡ����о�������Ñ��@ȡĿ�˕�����Ч�ʣ��Mһ������W���M����x���W����֪�R��չ�����ˌ���У�W�����x���n���M�Мʴ_��λ�������ÌW�������n�̵��u�r��ͬ�r�Y(ji��)�ϻ�(li��n)�W(w��ng)�ЌW���Ğg�[��(sh��)��(j��)�������c�����dȤһ�µ����]�������څf(xi��)ͬ�^�V�����]�㷨���A�Ϙ����OӋ�˿�ҕ���Ă��Ի��D�����]ϵ�y(t��ng)��
������ϵ�y(t��ng)��(j��ng)�^���W���W���О���A̎������ְl(f��)�]��(li��n)�W(w��ng)����W���@ȡ�D����Ϣ����Ҫ;�������c�����Ô�(sh��)��(j��)�ھ��g�@ȡ���W���Ğg�[�vʷ�����u�����Ȕ�(sh��)��(j��)�Y(ji��)�ϣ�ʹ��Python�Z�Ԍ���(sh��)��(j��)�M���A̎����̎��Gʧ�Ĕ�(sh��)��(j��)�cƫ�xֵ�������dȤ�A��ֵ�c��(sh��)��(j��)���P(li��n)�Է�����ץȡ�W�����Ի����]�����б����ɴ���Ʌf(xi��)ͬ�^�V���]���^�̣����������D����Ϣ��ϵ�y(t��ng)ƽ�_��չ�F(xi��n)��
�����W���W���О�����c�dȤ�A��Ӌ���Ը�У�W���W���О锵(sh��)��(j��)����A�����W������n�̳ɿ��c�x���n�n�̳ɿ��M�з�������ȡ�W���ă�(y��u)���c���W�ƣ��M�ЌW���W�ƙ�ֵ�����c�әಢ�����f(xi��)ͬ�^�VͶƱģ�ͣ��Ԍ��F(xi��n)�W���ȡ�L�a�̵Ă��Ի��D�����]����Σ����W�����x�n�����c�W�����Ի��x���n��e�Ȕ�(sh��)��(j��)�M�з����������W����֪�R�P(li��n)�D�V���ԌW�����c��(y��u)��e�����ġ����I(y��)�c�dȤ�錦�ȳߘˣ��_���ַ����M�ж�S���dȤ�P(li��n)��Ŀ�ġ�
����ͬ�rϵ�y(t��ng)�����Ñ��ṩ��x�dȤA���x���c�dȤ���T�D���x���c�u�֣�����x�dȤ�c��Ϣ�c֪�R�P(li��n)�D�V�Y(ji��)���M�г����Y�x��������S��(sh��)��(j��)���u���wϵ�c���څf(xi��)ͬ�^�V�ĸ��ʾ��ģ�ͣ���K���F(xi��n)�W���dȤ�A��ֵ�ij���Ӌ�㡣�D����Ϣ�ӑB(t��i)�@ȡ�c��(sh��)��(j��)�A̎���ڈD����Ϣ�ĄӑB(t��i)�@ȡ�ϣ�ʹ�û���Python��BeautifulSoup������x���g�����T�ĈD����Ϣ�W(w��ng)վ�Ĕ�(sh��)��(j��)�M�ЄӑB(t��i)�ھ��D����������Լ�ÿ�Ճ�(y��u)�x�D�������M�И˺�퓵Ķ��r�ӑB(t��i)��ȡ��ᘌ�xpath��ȡ�^���г��F(xi��n)�IJ�Ҏ(gu��)����ȡ�Y(ji��)�����ü��϶�λӳ��ķ�������K�Զ��xxpath���F(xi��n)���Y(ji��)��攵(sh��)��(j��)ץȡ��
����ͨ�^���W���dȤ�A��ֵ�ķ�������ץȡ�ĈD����(sh��)��(j��)�M�Д�(sh��)��(j��)��ϴ�����Ƚ�(j��ng)�^���������D���P�I�~�M�Ы@ȡ���ų��W���P(li��n)�̶ȵ͡��ɿ��Ե��Լ��؏��ھ�Ȇ��}�Ĕ�(sh��)��(j��)�����������رȺY�x���P�I�Ԕ�(sh��)��(j��)��������Ӌ��Y�x��(sh��)��(j��)�Ŀɿ����c�P(li��n)�ȡ���ƫ���^��Ĕ�(sh��)��(j��)�M���ų���̎��Gʧ�Ĕ�(sh��)��(j��)��̎��ƫ�xֵ������ڔ�(sh��)��(j��)�y(t��ng)Ӌ���dȤָ�˵�Ӌ�㡢�Լ���(sh��)��(j��)�P(li��n)�Է����춨��(sh��)��(j��)���A��
������������ϴ�D����(sh��)��(j��)����Ϣ�惦���_����(sh��)��(j��)�D(zhu��n)�Q���˜ʻ����wһ���Ĝʴ_�ԡ��������څf(xi��)ͬ�^�V�ĈD�����]ϵ�y(t��ng)��ϵ�y(t��ng)�Ŀ�ҕ��ƽ�_��MVCģʽ�M�И������͑���ЈD�����]ϵ�y(t��ng)ʹ��Vue��ܡ����Ìӄt��ȡSSM����M���_�l(f��)���ڌ������ӌ��F(xi��n)�ⲿ�D���W(w��ng)վ�ӿڵī@ȡ�c�B�ӣ����ھ�?q��)W���dȤ�����ԣ������r���N������(sh��)��(j��)���F(xi��n)�˄ӑB(t��i)��ȡ���o�����c���C���Ե؎��Ӹ�У�W�������x���W�����dȤ��
�������Ռ��������xģ�K����(sh��)��(j��)����ģ�K�cϵ�y(t��ng)չʾģ�K�����֡����w�ģ����xģ�K�������Ñ��P(li��n)�Ⱥ��dȤ���ƶ�Ӌ�㷽������k�T����(n��i)�����Ñ��ĈD����(sh��)��(j��)����ƫ�þ�ꇙ���ֵ��С�M�Ы@ȡ���@ȡ��S�ȵĈD����(sh��)��(j��)Դ;��(sh��)��(j��)����ģ�K���ڔ�(sh��)��(j��)���Ќ��W���ČW���О锵(sh��)��(j��)�M��̎��������ͨ�^�f(xi��)ͬ�^�V�㷨Ӌ����W���W����Ҫ�@ȡ�D���ăA���ԡ�
�������ϵ�y(t��ng)չʾģ�K�����ڽ�(j��ng)�^�A̎����ϴ�ĈD����Ϣ���Y(ji��)�όW�����dȤ�A���P�I�~�Y�x�����x��ϵ�y(t��ng)�д惦�Ă��Ի����]�����������˾C����挢�W���О�����A�εľC�ϳɿ�������r�c�dȤ�A���ԈD�εķ�ʽչ�F(xi��n)�������Ñ�����Ѹ�١�ֱ�^�ز鿴�D�������P��Ϣ����ϵ�y(t��ng)�ڿ͑��ʹ��Vue����M��ҕ�D�����_�l(f��)�������Ռ�Ӌ��ĈD�����]�Y(ji��)��ͨ�^API�ӿ��ڂ������]����M���xȡ�cչʾ����Kϵ�y(t��ng)����ɷֲ�ʽ���𡢶��M�̡�ؓ�d����؈D�����]ϵ�y(t��ng)�Ę����c(li��n)ͨ��
�������Y(ji��)
�����Լ��l(f��)�W�������W����(n��i)�����]��Ŀ�ˣ����ĽY(ji��)�όW����x�dȤ�A��������څf(xi��)ͬ�^�V�c�P(li��n)Ҏ(gu��)�t�Ă��Ի��D�����]ϵ�y(t��ng)������(j��)�dȤ�A��ֵ�M�Д�(sh��)��(j��)���x���������Ի��f(xi��)ͬ�^�V���]�㷨���õ��W���D�����]ƽ�_�Ľ��O�С���������ߌW��֮�g�����ī@ȡЧ���c��Ϣ�����������W������������x����Ҫ�Բ��M���䌦���Ի��������]�����Ķ����l(f��)�W������x�W��֪�R���dȤ����һ���о��У����Mһ���ӏ��c��У�D���^��(sh��)��(j��)�YԴ���O(li��n)ϵ��������ÌWУ�D���^���ڌW���Č��I(y��)�D����e�����Լ��W���ڈD���^��醕�����ӛ䛣��Mһ�����Ʊ���Ӌ�㷽�������ṩ�����Ի��ĈD���^���]ƽ�_��
�������ߣ�������;���t�B;������;������

�D(zhu��n)�dՈע�����l(f��)��W�gՓ�ľW(w��ng)��http://www.zpfmc.com/jjlw/26829.html
